テキストマイニングの概要
(1) 「テキストマイニング」と言う言葉が、語られ始めたのが1996年頃。
(2) 当初は、データマイニングの一分野とする見方が強かったが、現在は、独立した技術分野として捉えられている。基本的な相違は以下の通り。
a) 文章は多様な分類が可能であり、分析者が分類方針を発見して設定する必要がある。(数値情報は、数学的な評価による自動分類が可能だが、文書情報は人間の判断が必須)
b) テキストマイニングツールは、知的作業(分類方針の策定と条件設定等)を支援するシステムであり、如何にスムーズに人間を支援できるかがポイントとなる。
(3) 「お客様の囲い込み戦略」の比重が増す経済環境の中で、「お客様の声」を直接分析するツールとして、市場の拡大と技術進化の途上にある。
(4) テキストマイニングのルーツは米国だが、日本の経営風土で育まれて発展途上にあり、技術展開及びビジネス展開の両面で日本が最もリードしている。
日本型顧客志向経営の基幹技術として、世界に発信できる可能性がある。
お客様の声を経営に生かす「顧客志向経営」の実現
テキスト分析手法の区分
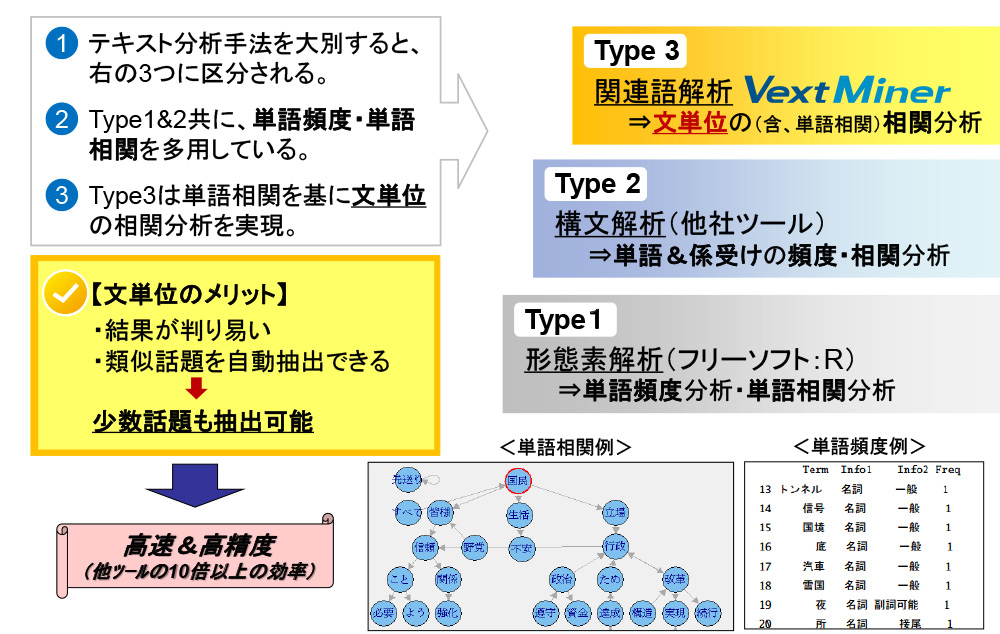
日本では様々な分析ツールが販売されていますが、大きく分けるとType1~3の3つのグループに分けられます。
Type1&2(他社ツール):形態素解析&構文解析
単語もしくは係り受けの頻度・相関分析を基に、テキストを分析する方法です。
テキストを分類するためには、煩雑な辞書作成を行う必要があり、労力を要します。
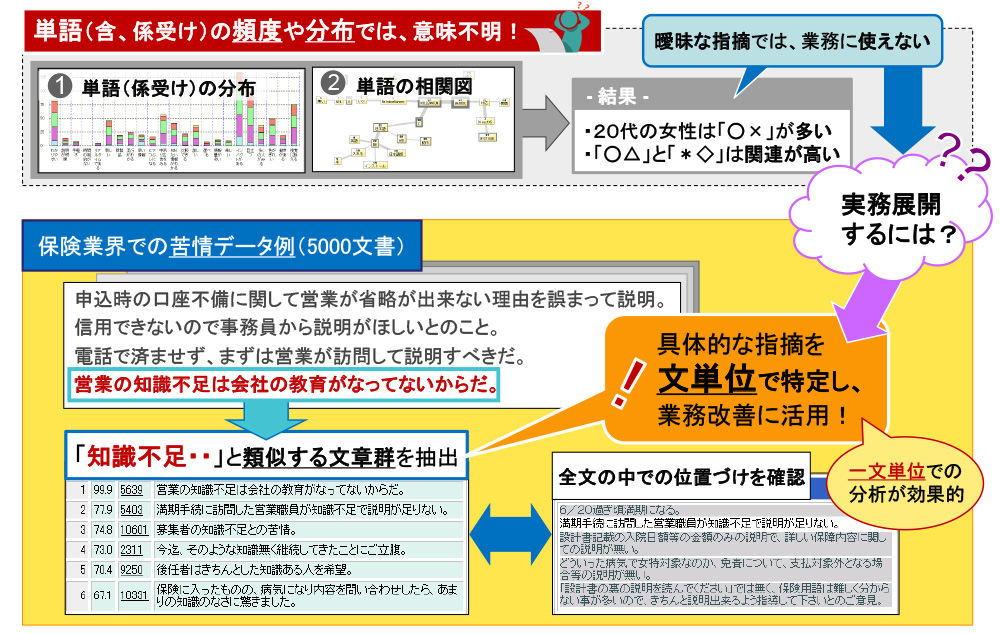
Type3(VextMiner):文単位の相関分析
VextMinerは、Type1&2のツールとは異なり、文単位で類似度を判断して分析する手法です。
文単位での分析の直接的なメリットは、
①類似する文章同士で自動分類できる為、分類結果が非常に分かり易い。
②文単位で分析できる事により、予め内容を特定できない少数話題も自動的に抽出する事ができる。の2点です。
さらに上記の機能を組合わせる事で、詳細な分析を迅速に行う事ができ、高速かつ高精度な分析ツールとなっています。
文単位で分析するメリット