自動学習機能(森を見る技術)とは?
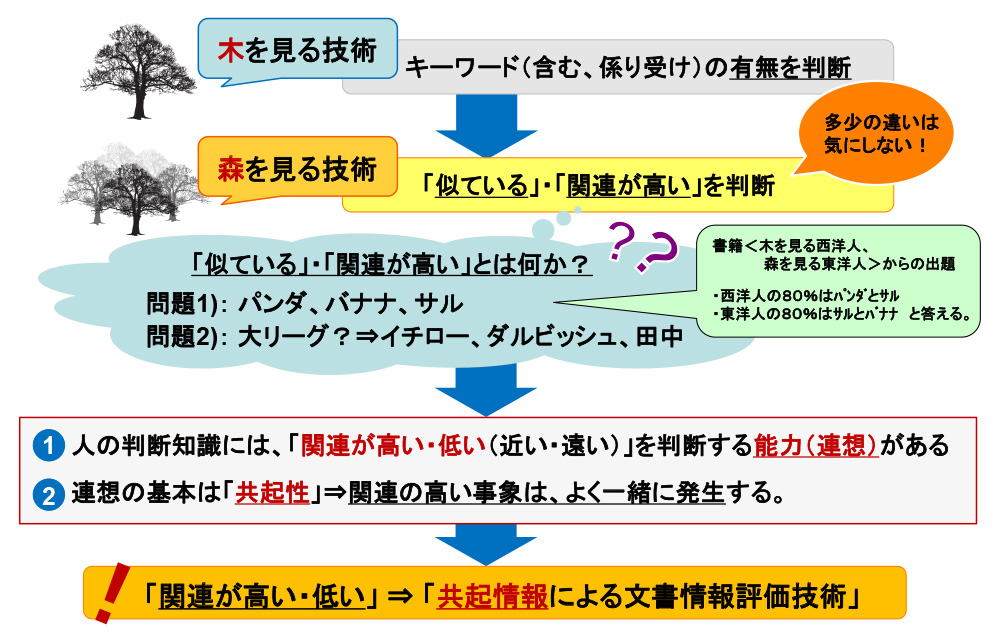
「木を見る技術」が、「単語や係り受けの有り・無し」を判断するのに対し、「森を見る技術」は「関連の高さ・低さ」を判断します。関連度を評価する重要な指標が「共起情報」で、これは「関連の高い事象は同時に出現する頻度が高い」という経験則を数値化したものです。事例として、「バナナとサルの関連度が高い」や「大リーグと聞けば、イチロー選手や田中選手をすぐに連想する」等を示していますが、頻度高く同時に見聞きしている事象に対し、我々は感覚的に関連が高いと判断しています。
こうした人間が持つ知識生成のプロセスを、実際の文書情報に適応したのが「森を見る技術」です。
(1) 自動学習機能
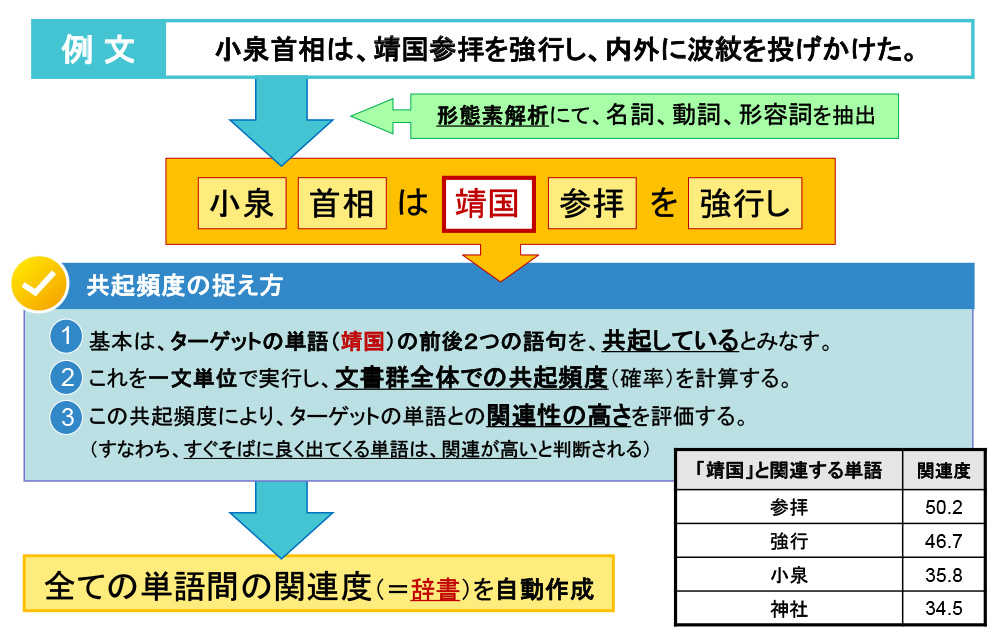
例として、「小泉首相は、靖国参拝を強行し、内外に波紋を投げかけた。」という昔の記事を用います。VextMinerは、まず形態素解析を行って文章を品詞分解し、「小泉」(名詞)・「首相」(名詞)・「は」(助詞)等に分割します。文章の構成上で重要な品詞は、名詞・動詞・形容詞ですので、この3品詞を基に共起性の分析を行います。
ここで、「靖国」という単語に着目をした場合の例を図に示すと、「靖国」の前後2単語(助詞を除いた名詞、動詞、形容詞)をチェックします。すると「小泉」・「首相」と「参拝」・「強行し」の4単語が「靖国」に対し、「一回共起した」事が判ります。
分析対象としたデータは某経済新聞1年間分ですが、約10万記事あり、その中で「靖国」が出て来た箇所は約5000箇所存在しました。さらにその中で、前後2単語に出現した単語を全て抽出して、頻度の高い順で並べると、「関連度」を測ることが出来ます。その結果は、「参拝(関連度:50.2)」「強行(46.7)」「小泉(35.8)」「神社(34.5)」となりましたが、これはその当時、小泉首相が靖国参拝を強行したという記事が、数多く書かれた事が原因と推測されます。こうした事態がなければ、靖国⇒靖国神社なので、「神社」との関連度が一番高くなる筈でした。
VextMinerでは、上記の分析作業を全ての名詞・動詞・形容詞に対して実施し、自動学習を行います。新聞1年間ですと5~7万語程度の単語が出現しますが、その全単語を自動抽出し、相互の関連度を極めて高速に学習する仕組みになっています。
(2) 学習知識(=辞書)は変化する
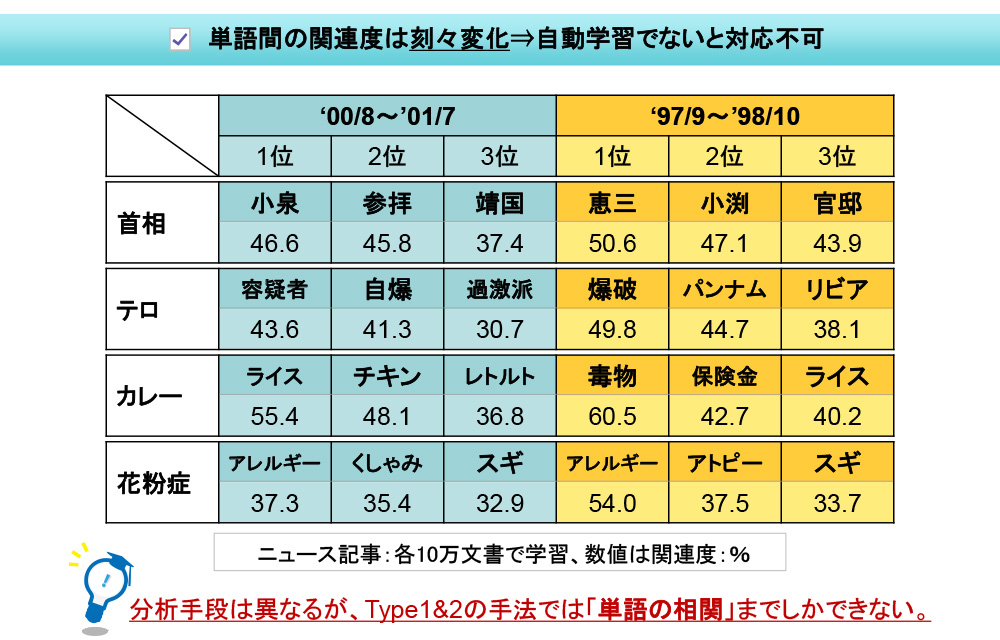
前述の自動学習機能を、某経済新聞の実データに適用した際の結果を示します。左が00年~01年、右が97年~98年です。各々1年間分の記事を自動学習させ、「首相」「テロ」「カレー」「花粉症」と関連が高い単語を比較しています。
「首相」は、当時の首相の名前が上位に表れるため、違いが明確です。「テロ」は00年度になると、「自爆」「過激派」が出て来ました。「カレー」は、97年度当時「毒物」や「保険金」と関連が高く、これは和歌山毒物カレー事件が連日新聞に掲載された事が原因となっています。00年度ではこうした記事が無くなったために、「カレー」⇒「ライス」「チキン」「レトルト」と、ごく普通に連想される単語が上位にランキングされています。「花粉症」では、両年度共に「スギ」や「アレルギー」との関連度が高く、いつも同じ文脈で用いられている事が判ります。
このようにVextMinerの自動学習機能は、「与えられた文章群の中から単語の関連度を自動的に学習し、知識として活用する事が可能」で、刻々変化する話題に対しても自動的に対応できるのです。
(3) 文書のベクトル化手法
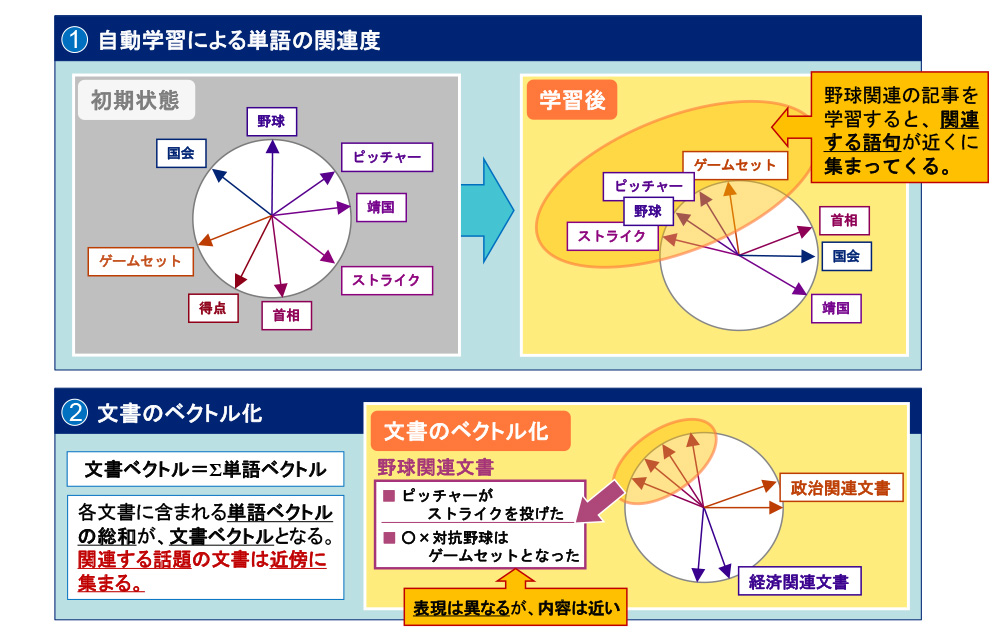
ただし最終的に、我々が欲しいのは単語の関連度ではなく文章間の関連度です。例として、「ピッチャーがストトライクを投げた」「○×対抗野球はゲームセットとなった」を示すと、この両文章に共通する単語はひとつもありませんが、誰でも「野球関連の記事」と判断ができます。この判断を、どうやってシステム化するか?がポイントです。
前述の自動学習をすると、初期状態ではバラバラだった単語は、野球関連の記事を基に学習し、関連の高い語群がベクトル空間上で近くに集まって来ます。各文章は、多くの単語を含んでいますが、文章のベクトルは各単語ベクトルの総和で表されます。
その結果、「野球」「ゲームセット」「ピッチャー」等は関連が高いと判断され、それらの語句を含んでいる文章同士も関連が高いと判断する事が出来ます。少なくとも、この両文章は、政治や経済の文章より遥かに関連が高いという事をシステムが判断できるのです。
以上の様に、まず単語間の関連度を分析して文章のベクトル化を行い、目標である文単位での関連度をシステムが把握をする事が可能となります。
(4) 文単位の分析による類似話題の自動抽出例
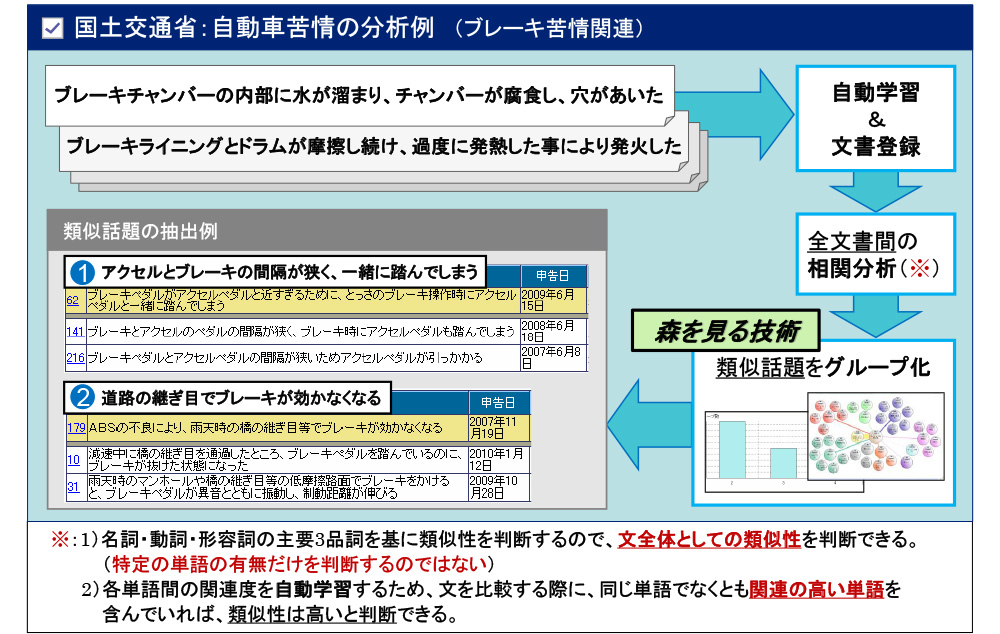
実例として、国土交通省のホームページに掲載されている自動車苦情データを分析した結果を示します。「(1)アクセルとブレーキの感覚が狭く、一緒に踏んでしまう」「(2)道路の継ぎ目でブレーキが効かなくなる」という趣旨の文章の集まりを、あらかじめ辞書を用意する事なく自動学習させた結果から抽出出来ています。VextMinerの特徴として名詞、動詞、形容詞の主要三品詞(文書全体の約80%を占める)を自動学習して、文章全体の類似性を判断する事が可能なため、このような結果が得られるのです。
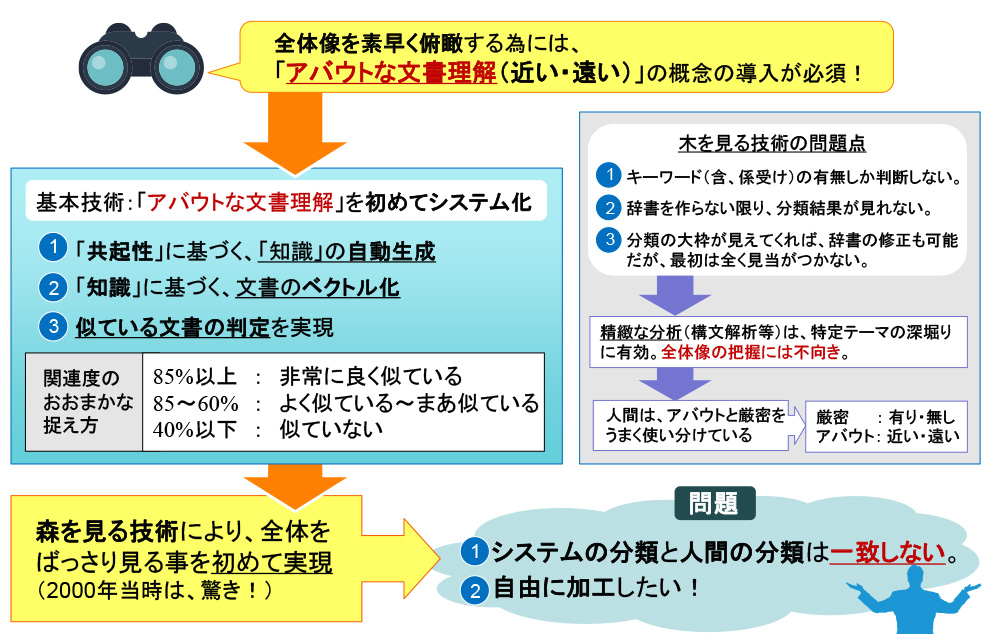
(5) 「森を見る技術」のまとめ
前述の「森を見る技術」は、文章群の全体を俯瞰して見る事に適しています。何万件もある文章を幾つかの大きな塊として見るためには、単語の有り無し情報(木を見る技術)では駄目なのです。「森を見る技術」を使えば、「話題を30個に分けろ」と指定をするだけで、システムが似ている順に自動的に分けてくれるという大きなメリットが生まれます。
但し、人間がする様に、「森を見る技術」と「木を見る技術」はうまく使い分ける必要があります。他のツールでは、「森を見る技術」を持たないので、全体をバッサリと見ることが非常に難しいのです。この技術を2000年当時に発表した際には、非常な驚きを持って迎えられました。「アンケート情報を30個の話題に分けると、ほぼ似た様な表現ごとに自動で分けてくれる。これは凄い!」と喜ばれたのですが、同時に問題点も判明しました。
その問題とは、システムが出す分類と、分析者が分類したい内容が必ずしも一致しない事です。分類を行う際には「分析者の意図」を反映する事が必要なため、自動分類結果を自由に加工したいという要望が生まれ、「クラスタマップ」機能を開発するに至りました。